RFC: Updated Kafka Architecture for `pnow-ats-v2`
RFC: Updated Kafka Architecture for pnow-ats-v2
- Authors: - Prathik Shetty(@pshettydev)
- Date: - 2025-07-09
- Status: Accepted
Abstract
The present Kafka platform, which is established in the production environment, is extremely unstable. It is not scalable, nor can the services fully rely on this system. Which makes it extremely risky and dangerous. The services using this event streaming platform will face constant errors or, even worse, loss of data.
Our present Kafka setup was nothing less than a "jugad". Like trying to fit 10-15 people in one auto rickshaw.
Hence, this RFC proposes for redesign of the Kafka architecture, implementing a robust 6-node cluster, best suited for production environments, especially for our project. This design will not only address current stability issues but also provide a future-proof foundation capable of accommodating increased throughput demands as additional microservices adopt our event streaming platform.
Motivation
Our initial Kafka implementation was deployed as a minimal viable solution due to time and resource constraints. This approach was appropriate for the original scope, which anticipated limited service integration and modest message volumes. This architectural mismatch has resulted in cascading failures, data inconsistencies, and operational overhead that impact both system reliability and team productivity.
Failure was inevitable. A system that was started as a proof of concept was being used extensively in production.
A comprehensive redesign has become imperative to establish a stable foundation for our event streaming infrastructure, ensure business continuity, and enable the continued evolution of our microservices ecosystem.
Approaches
The initial approach was to provide more compute resources to the container and implement retry mechanisms, such that the Kafka container does not exit. However, soon came to realise that it would just be a temporary hot fix. Like applying a band-aid on top of a huge wound.
Then after going through a bunch of resources, I came along this documentation, which clearly states:
While it's technically possible for a single server to act as a both broker and a controller, this configuration is not recommended for production environments due to performance and fault-tolerance considerations
And that is exactly what was being done. If it was for testing purpose then having a server to act as both broker and service woudl have been fine. However if there are multiple services and servers that are going to be interacting with it, then the broker and a controller should be separated.
So we decided to come up with the approach of 6-node cluster, which is a cluster composed of three brokers and three dedicated controllers. This separation will allow us to observe the communication patterns between the different components
Proposal
Cluster Setup
A 6-node cluster is:
- 3 controllers (dedicated KRaft nodes responsible for metadata and coordination).
- 3 brokers (handling client interactions and data replication).
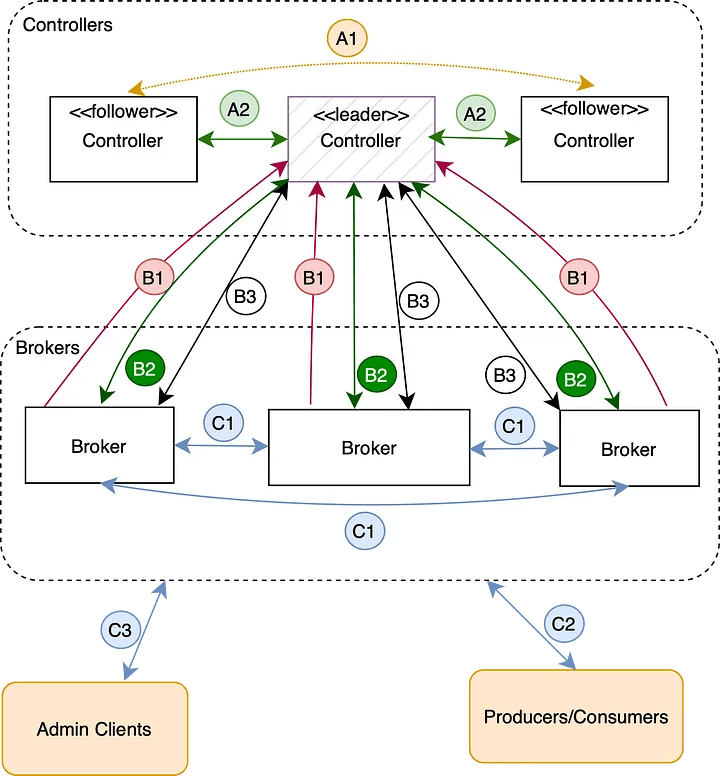
In KRaft-based Kafka setup, controllers form a Raft quorum — a distributed consensus group where one controller is dynamically elected as the leader, while the others act as followers. The leader is the source of truth for the metadata for the cluster.
Controller-to-Controller Communication.
- Arrow A1 — Leader Election: When the current leader controller fails, the followers coordinate using the KRaft protocol to elect a new leader. This ensures high availability and consistency in metadata management.
- Arrow A2 — Metadata Replication: The leader controller maintains the source of truth for all metadata (topics, partitions, brokers, etc.). It replicates updates to follower controllers to ensure they remain synchronized and are ready to take over if leadership changes.
While the implementation differs, this leader-follower pattern is conceptually similar to how ZooKeeper managed metadata and coordination in earlier Kafka versions.
Broker-to-Controller Communication:
Brokers communicate only with the current controller leader. This simplifies the interaction model.
- Arrow B1 — Heartbeats: Brokers send periodic heartbeat messages to the leader controller to signal that they are healthy and operational.
- Arrow B2 — Metadata Updates: Brokers receive metadata updates from the controller leader to stay synchronized with the current cluster topology and configuration.
- Arrow B3 — Active Metadata Requests: Brokers also initiate requests to the controller leader — such as creating new topics or registering themselves — whenever active changes to the cluster state are required.
Broker-to-Broker and Client Communication
In addition to controller communication, brokers also interact directly with each other and with clients.
- Arrow C1 — Data Replication
Brokers replicate partition data among themselves to ensure durability and high availability, based on the configured replication factor. - Arrow C2 — Producer/Consumer Requests
Clients (producers and consumers) interact directly with brokers to send or receive messages. The metadata helps clients discover the correct broker to contact. - Arrow C3 — Admin Requests
Clients also send administrative requests — such as creating topics, deleting topics, altering configurations, or describing cluster state — directly to brokers. Brokers forward any request that modifies the cluster metadata — for example, creating topics, deleting topics, altering configurations, or changing partition leadership — to the controller leader.